What is ISR (In-Sync Replicas) in Kafka?
What is ISR?
ISR (In-Sync Replicas) is a fundamental concept in Kafka that represents a set of replicas that are in sync with the leader partition. This set includes the leader replica itself and all follower replicas that are actively syncing with the leader. The ISR mechanism is crucial for ensuring high availability and data consistency in Kafka.
How ISR Works
1. Basic Concepts
Each partition's ISR list contains two types of replicas:
- Leader Replica: The primary replica that handles all read and write requests
- Follower Replicas: Secondary replicas that replicate data from the leader
Key characteristics of the ISR mechanism:
- ISR membership is dynamic and automatically adjusts based on replica sync status
- Only replicas in the ISR are eligible to become the new leader
- With
acks=all, writes are considered successful only after all ISR replicas confirm - Kafka uses ZooKeeper to persist and synchronize ISR changes
Here's a concrete example: Consider a partition with 3 replicas:
- Replica on Broker-1 is the Leader
- Replica on Broker-2 is in sync (lag < 5s)
- Replica on Broker-3 is lagging (20s behind)
In this case, the ISR list only includes replicas on Broker-1 and Broker-2. The replica on Broker-3 is temporarily removed from ISR. Once it catches up, it will automatically rejoin the ISR list.
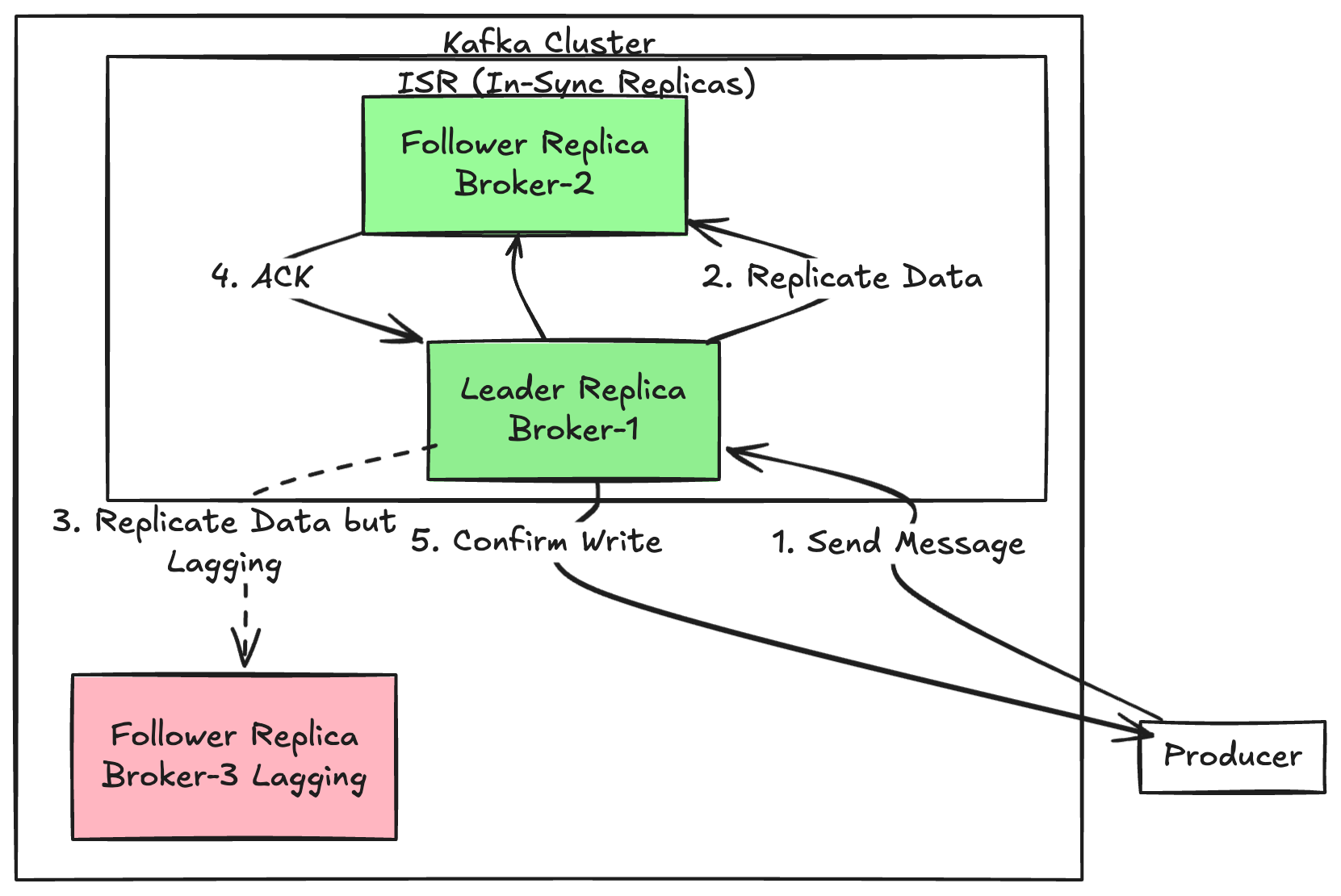
2. ISR Membership Rules
Requirements to join ISR:
- Follower's message lag must be within acceptable limits (controlled by replica.lag.time.max.ms)
- Follower must maintain active fetch requests to the leader
Conditions for removal from ISR:
- Replica falls behind beyond the allowed time threshold
- Broker hosting the replica fails
- Replica encounters synchronization errors
ISR Configuration
1. Core Settings
# Maximum allowed time for replica lag
replica.lag.time.max.ms=10000
# Minimum number of in-sync replicas required
min.insync.replicas=2
# Whether to allow non-ISR replicas to become leader
unclean.leader.election.enable=false
2. Producer Settings
# Ensure writes to all ISR replicas
acks=all
# Number of retry attempts
retries=3
ISR in Practice
1. Data Reliability
When producers use acks=all:
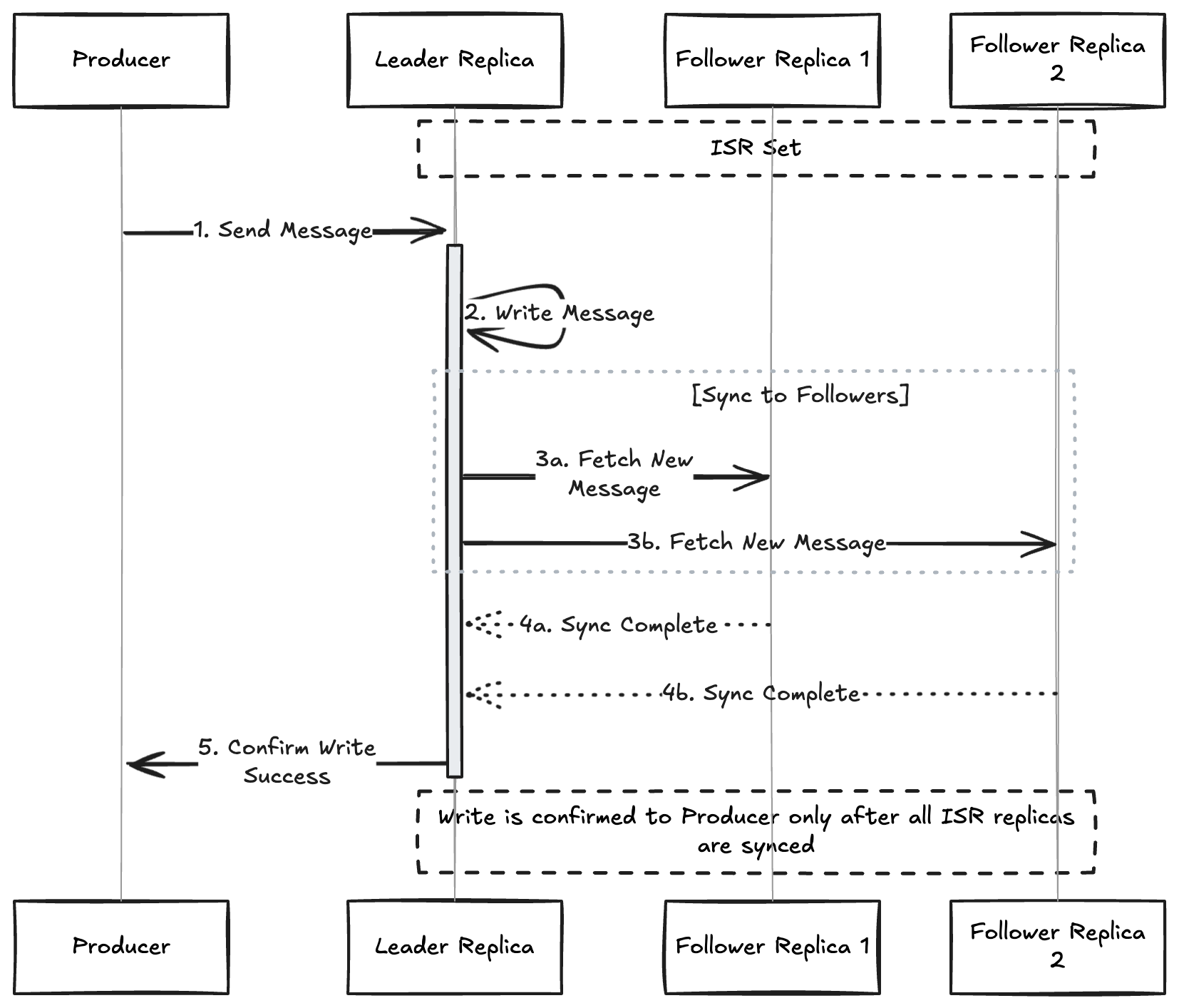
2. Leader Election
When the leader replica fails:
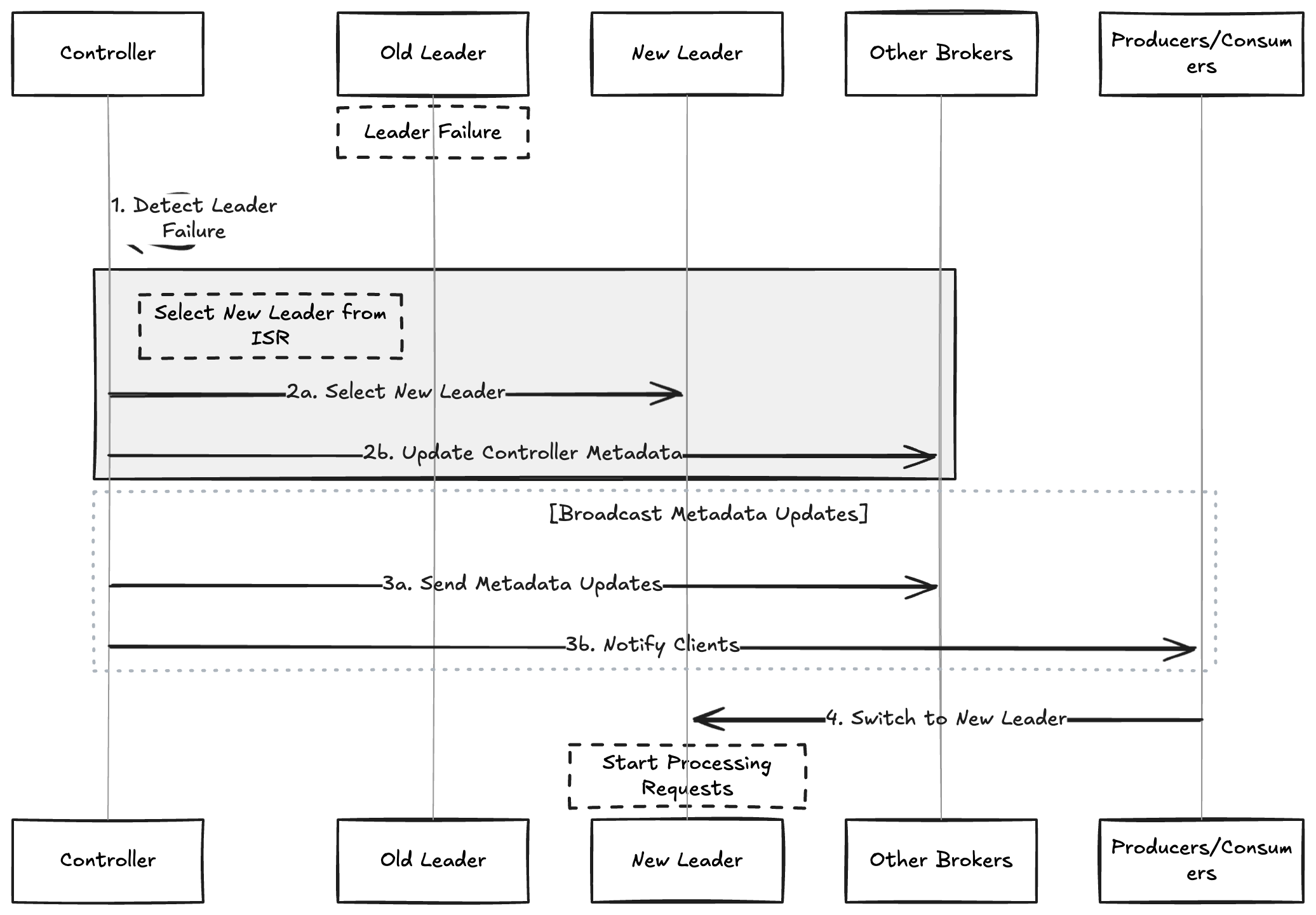
Common Issues and Solutions
1. Frequent ISR Shrinking
Common causes:
- Network latency spikes leading to sync timeouts
- High system load on follower nodes
- Extended GC pauses disrupting sync processes
- Disk I/O bottlenecks affecting write performance
Recommended solutions:
-
Parameter Optimization
- Increase
replica.lag.time.max.msfor networks with higher latency - Adjust
replica.fetch.wait.max.msbased on network characteristics - Increase
replica.fetch.max.bytesto optimize sync efficiency
- Increase
-
Follower Performance Optimization
- Monitor and address CPU usage spikes
- Optimize memory allocation and usage
- Consider SSD storage for improved I/O performance
- Isolate Kafka brokers from other resource-intensive services
-
JVM Optimization
- Select an appropriate GC algorithm for the workload
- Optimize heap size configuration
- Implement comprehensive GC monitoring
-
Network Optimization
- Ensure adequate network bandwidth
- Monitor and address network latency issues
2. Data Loss Risks
Critical scenarios:
- ISR set reduction to a single replica
- Enabled unclean leader election
- Network partitioning events
- Unexpected traffic surges
Prevention strategies:
-
Replica Management
- Maintain minimum of 2 in-sync replicas
- Disable unclean leader election
- Implement regular replica status monitoring
- Deploy balanced replica distribution
-
Monitoring Strategy
- Implement ISR size change monitoring
- Track replica synchronization metrics
-
Capacity Management
- Maintain adequate resource headroom
- Monitor cluster metrics
- Plan proactive scaling
Summary
The ISR mechanism is fundamental to Kafka's reliability and high availability. Successful implementation requires balancing data durability with performance requirements. Each deployment should be tuned according to specific use cases and operational requirements.
Related Topics: