How to Use Kafka Producer Retries?
Why Do We Need Retries?
In distributed systems, network failures and server outages are inevitable. Kafka is no exception. The Producer retry mechanism is designed specifically to handle these temporary failures gracefully.
How Producer Retry Works?
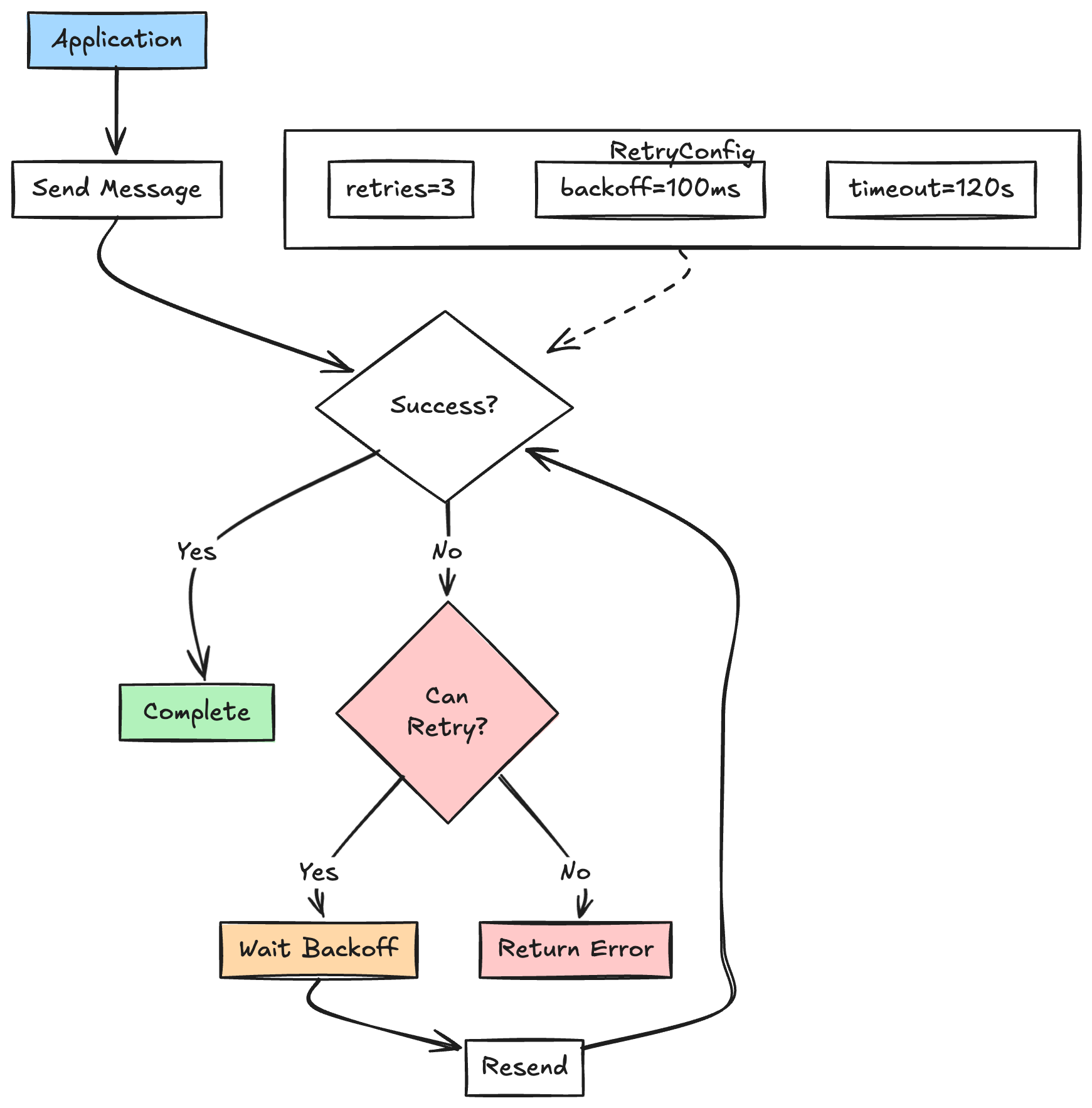
Key Configuration Parameters
1. retries
# Number of retry attempts
retries=3 # Retry 3 times
2. retry.backoff.ms
# Time between retries
retry.backoff.ms=100 # Base retry interval of 100ms
Note: Since Kafka 2.1, Producers use exponential backoff by default. The actual wait time increases with each retry:
- 1st retry: 100ms wait
- 2nd retry: 200ms wait
- 3rd retry: 400ms wait This prevents unnecessary rapid retries during sustained failures.
3. delivery.timeout.ms
# Total timeout for message delivery
delivery.timeout.ms=120000 # Wait up to 2 minutes
4. enable.idempotence
# Enable idempotence to prevent duplicate messages during retries
enable.idempotence=true
Strongly recommended for production environments. This ensures each message is written exactly once, even when retries occur.
Real-World Scenarios
Scenario 1: Network Hiccup
Here's how the retry mechanism handles network instability:
Send message ❌ Network timeout
↓
Wait 100ms and retry
↓
Retry successful ✅ Message delivered
Scenario 2: Broker Failover
When a broker fails, Kafka automatically elects a new leader:
Send message ❌ Leader unavailable
↓
Wait 100ms (while leader election happens)
↓
Retry sending ✅ New leader online, message delivered
Best Practices
-
Enable Idempotence
- Prevents message duplication during retries
- Set
enable.idempotence=true
-
Set Reasonable Retry Limits
- Based on your business requirements
- Avoid infinite retries
-
Monitor Retry Metrics
- Track retry counts
- Set up alerting thresholds
Key Takeaways
A well-configured retry mechanism ensures message reliability while avoiding performance issues from excessive retries. It's a crucial component of any robust messaging system.
Related Topics: