Kafka 中的 ISR(In-Sync Replicas)是什么?
Kafka
高可用
副本机制
分布式系统
什么是 ISR?
ISR(In-Sync Replicas,同步副本集合)是 Kafka 中的核心概念之一。它包含了所有与 Leader 副本保持同步的副本(包括 Leader 副本自己)。这个机制是 Kafka 保证高可用和数据一致性的关键。
ISR 的工作原理
1. 基本概念
每个分区的 ISR 列表中包含两类副本:
- Leader 副本:主副本,负责处理分区的读写请求
- Follower 副本:从副本,负责从 Leader 复制数据并保持同步
ISR 机制的核心特点:
- ISR 是动态变化的,会根据副本的同步状态自动调整成员
- 只有 ISR 中的副本才有资格被选举为新的 Leader
- 生产者的
acks=all时,只有 ISR 中所有副本都确认写入才算成功 - Kafka 通过 ZooKeeper 持久化并同步 ISR 的变更
以一个具体的例子来说明: 假设某个分区有 3 个副本,其中:
- Broker-1 上的副本是 Leader
- Broker-2 上的副本正常同步,延迟 5s 以内
- Broker-3 上的副本同步滞后 20s
那么此时的 ISR 列表就只包含 Broker-1 和 Broker-2 上的副本,而 Broker-3 的副本会被临时踢出 ISR。当 Broker-3 的副本重新追上进度后,它会被自动加回 ISR 列表。
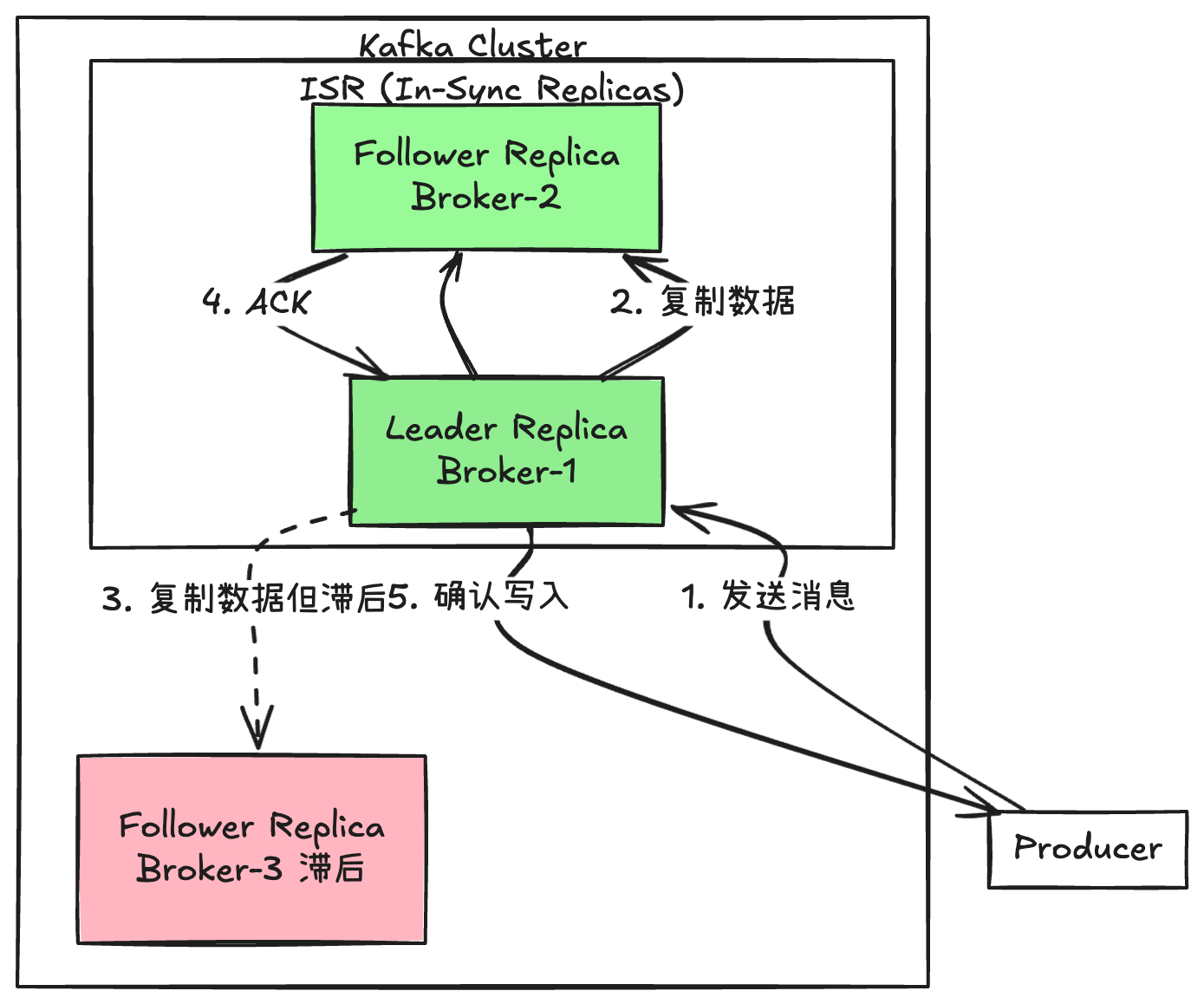
2. 副本如何进入和退出 ISR?
进入 ISR 需要满足以下条件:
- Follower 副本的消息滞后时间在允许范围内(由 replica.lag.time.max.ms 控制)
- Follower 副本能正常向 Leader 发送数据同步请求
以下情况会导致副本被踢出 ISR:
- 副本同步滞后超过允许的时间阈值
- 副本所在的 Broker 发生宕机
- 副本在同步过程中出现异常
ISR 的配置参数
1. 核心配置
# 副本允许的最大滞后时间
replica.lag.time.max.ms=10000
# ISR 中需要保持同步的最小副本数
min.insync.replicas=2
# 是否允许从 ISR 之外选举新的 Leader
unclean.leader.election.enable=false
2. 生产者相关配置
# 要求确保消息写入到所有 ISR 副本
acks=all
# 发送失败重试次数
retries=3
ISR 在实际场景中的应用
1. 数据可靠性保证
当生产者配置 acks=all 时:
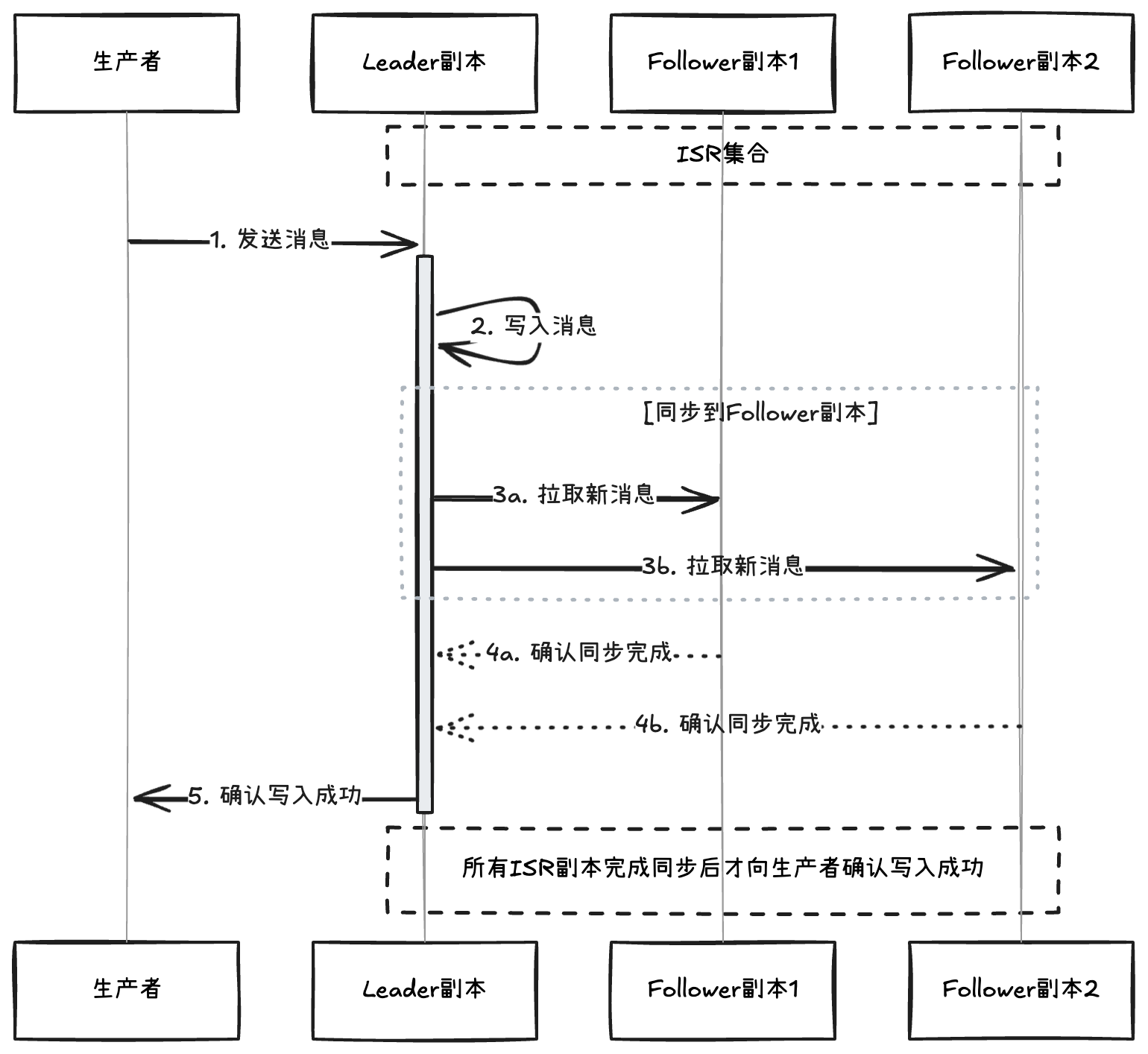
2. Leader 选举
当 Leader 副本失效时:
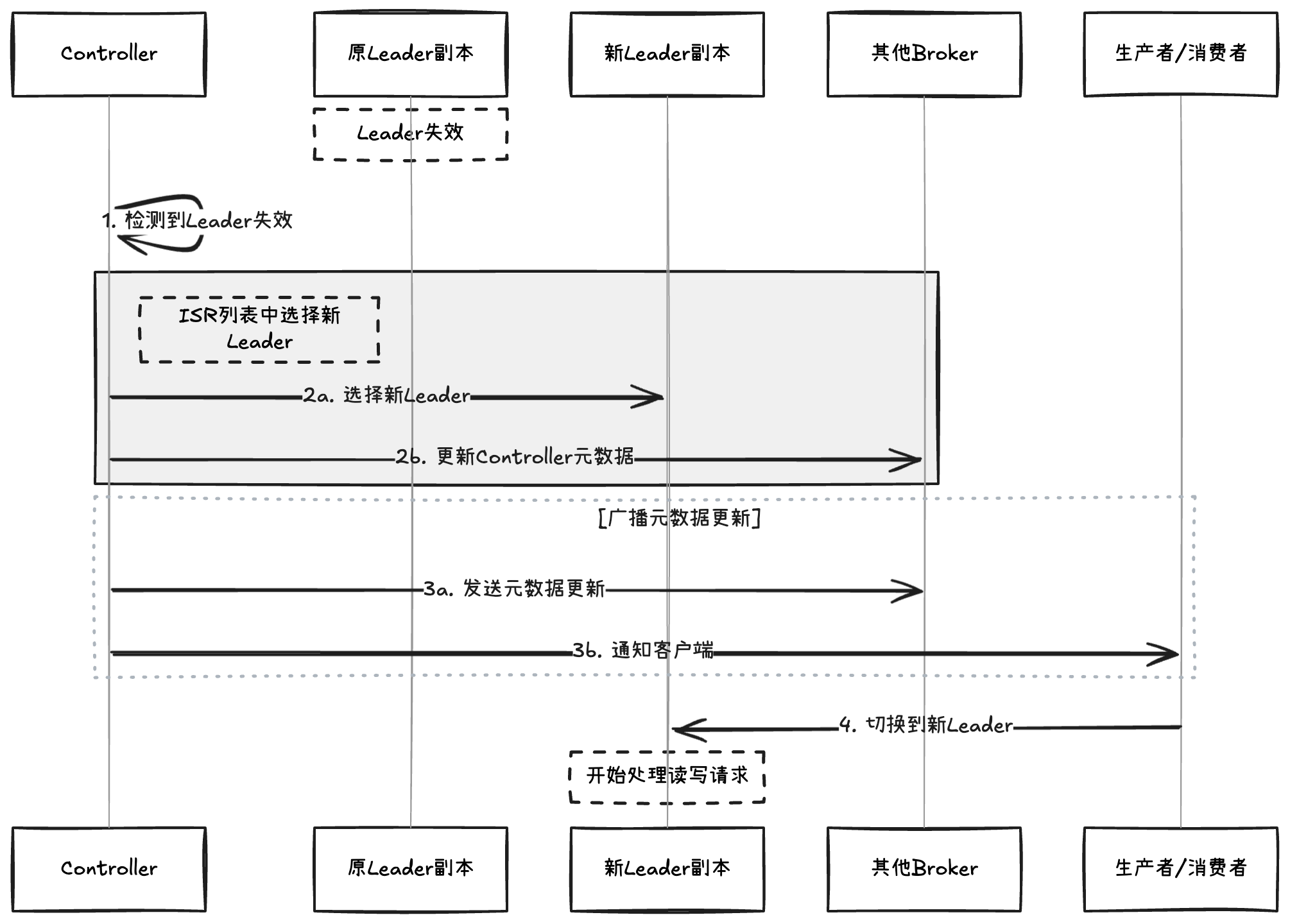
常见问题及解决方案
1. ISR 列表频繁变化
问题原因:
- 网络延迟波动:网络抖动或拥塞导致副本同步延迟增加,触发 ISR 收缩
- Follower 节点负载过高:CPU、内存或磁盘 I/O 压力导致副本同步变慢
- GC 停顿时间过长:JVM 垃圾回收导致服务暂停,影响副本同步效率
- 磁盘性能问题:磁盘 I/O 瓶颈导致消息写入和同步变慢
解决方案:
-
调整同步参数
- 适当调大
replica.lag.time.max.ms值,增加容忍度 - 根据网络状况设置合理的
replica.fetch.wait.max.ms - 适当增加
replica.fetch.max.bytes提高同步效率
- 适当调大
-
优化 Follower 节点性能
- 监控并优化 CPU 使用率
- 合理分配和限制内存使用
- 使用高性能磁盘或引入缓存机制
- 避免与其他重负载服务部署在同一节点
-
JVM 调优
- 选择合适的 GC 算法
- 调整堆内存大小和分代比例
- 开启 GC 日志监控
-
网络优化
- 确保足够的网络带宽
- 监控网络延迟和丢包率
2. 数据丢失风险
风险场景:
- ISR 中仅剩一个副本:其他副本同步失败或宕机,导致数据冗余度降低
- 启用非同步副本选主:允许非 ISR 中的副本成为 Leader,可能导致数据丢失
- 网络分区:网络故障导致分区通信中断
- 突发流量:消息突增导致副本同步压力变大
防范措施:
-
副本管理
- 合理设置最小同步副本数(建议至少为 2)
- 禁用非同步副本选主(设置
unclean.leader.election.enable=false) - 定期检查副本状态和同步情况
- 实施副本均衡策略
-
监控告警
- 设置 ISR 列表大小变化告警
- 监控副本同步延迟指标
-
容量规划
- 预留足够的硬件资源冗余
- 定期评估集群容量
- 制定合理的扩容方案
小结
ISR 机制是 Kafka 实现高可用和数据一致性的核心机制。合理配置和监控 ISR,对于搭建可靠的 Kafka 集群至关重要。在实际应用中,我们需要根据业务场景和可用性要求,在数据可靠性和性能之间找到最佳平衡点。
相关推荐: