Kafka 如何进行日志压缩(Log Compaction)?
Kafka
日志压缩
数据存储
什么是日志压缩?
日志压缩(Log Compaction)是 Kafka 提供的一种特殊的数据清理机制。它不同于普通的数据清理策略,会为每个消息键(Key)保留最新的值,删除旧值。这种机制特别适合存储需要保持最新状态的数据,比如数据库的变更记录或系统配置信息。
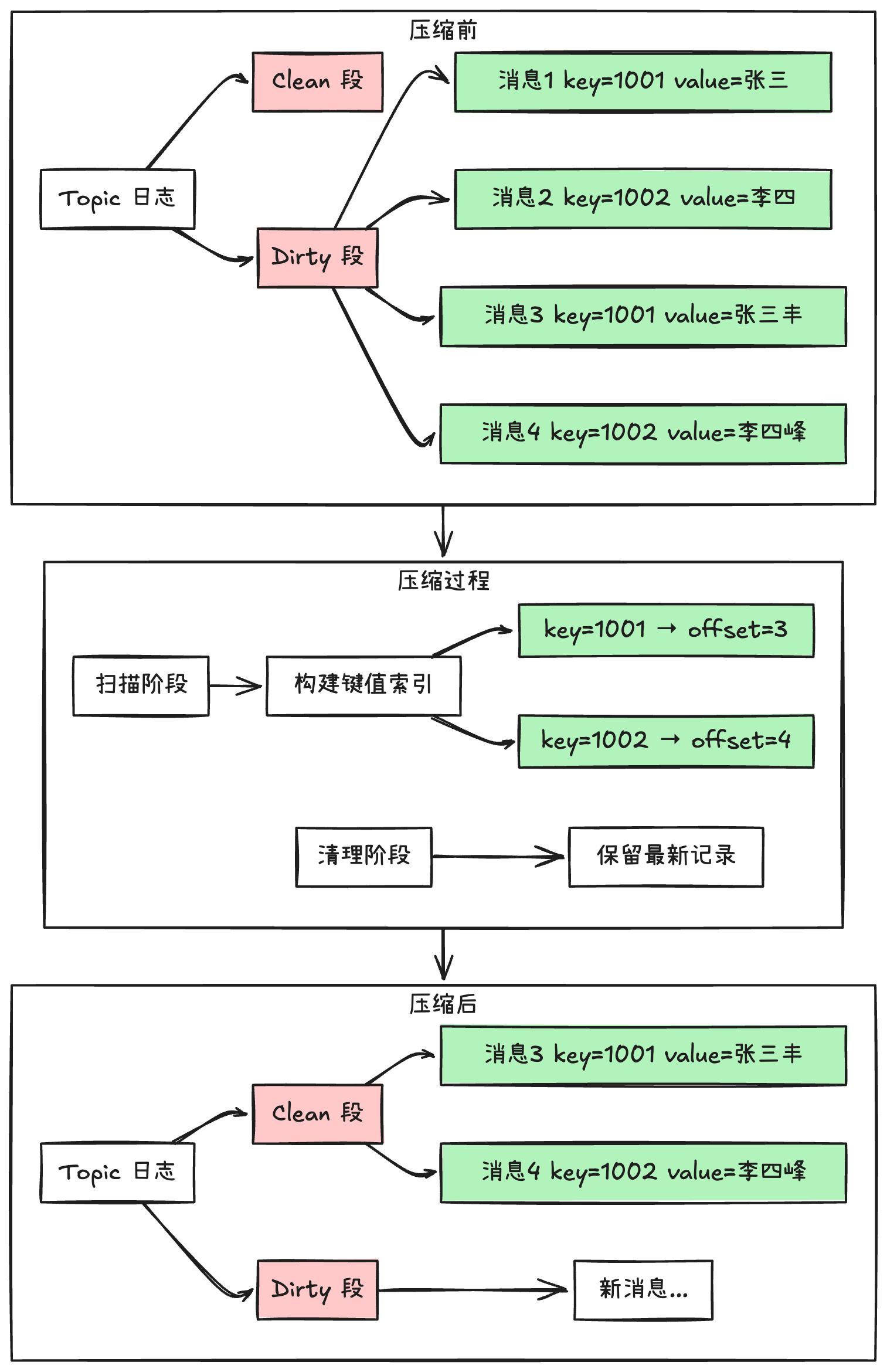
日志压缩的工作原理
1. 日志的存储结构
Kafka 把日志分成两个部分:
- Clean 段: 已完成压缩的数据
- Dirty 段: 待压缩的新数据
2. 压缩的执行过程
压缩分为两个主要阶段:
-
扫描阶段:
- 遍历 Dirty 段中的所有消息
- 为每个消息键建立索引,记录最新位置
-
清理阶段:
- 只保留每个键的最新记录
- 清理掉重复的旧记录
- 确保消息的先后顺序不变
3. 压缩的触发时机
系统会在以下情况触发压缩:
- 未压缩数据比例超过阈值
- 达到预设的时间间隔
- 手动触发压缩操作
如何配置日志压缩?
以下是关键的配置参数:
# 开启日志压缩功能
log.cleanup.policy=compact
# 设置压缩检查间隔
log.cleaner.backoff.ms=30000
# 设置压缩触发阈值
log.cleaner.min.cleanable.ratio=0.5
# 设置压缩线程数
log.cleaner.threads=1
适用场景
日志压缩最适合以下应用场景:
1. 数据库变更记录
以用户信息更新为例:
- 新增用户记录:
key=1001, value=张三 - 修改用户信息:
key=1001, value=张三丰 - 压缩后结果:
key=1001, value=张三丰
2. 系统配置管理
以连接数配置为例:
- 初始配置:
key=最大连接数, value=100 - 配置更新:
key=最大连接数, value=200 - 压缩后结果:
key=最大连接数, value=200
3. 状态数据存储
- 维护实体的最新状态
- 节省存储空间
使用注意事项
在使用日志压缩时,需要注意以下几点:
-
消息必须包含 Key
- 压缩是基于 Key 进行的
- 没有 Key 的消息不会被压缩处理
-
对系统性能的影响
- 压缩过程会占用系统资源
- 需要合理设置压缩参数
-
消息顺序的保证
- 同一个 Key 的消息顺序不变
- 不同 Key 之间的顺序可能变化
小结
Kafka 的日志压缩机制为我们提供了一种智能的数据清理方案。它特别适合那些只需要保留最新状态的场景,既能节省存储空间,又能保证数据的可用性。合理使用这个功能,可以让 Kafka 集群运行得更加高效。
相关推荐: