如何使用 Kafka Producer 的重试?
Kafka
分布式系统
消息队列
可靠性
为什么需要重试机制?
在分布式系统中,网络故障、服务器宕机等问题在所难免。Kafka 也不例外。Kafka Producer 的重试机制就是为了解决这些临时性故障而设计的。
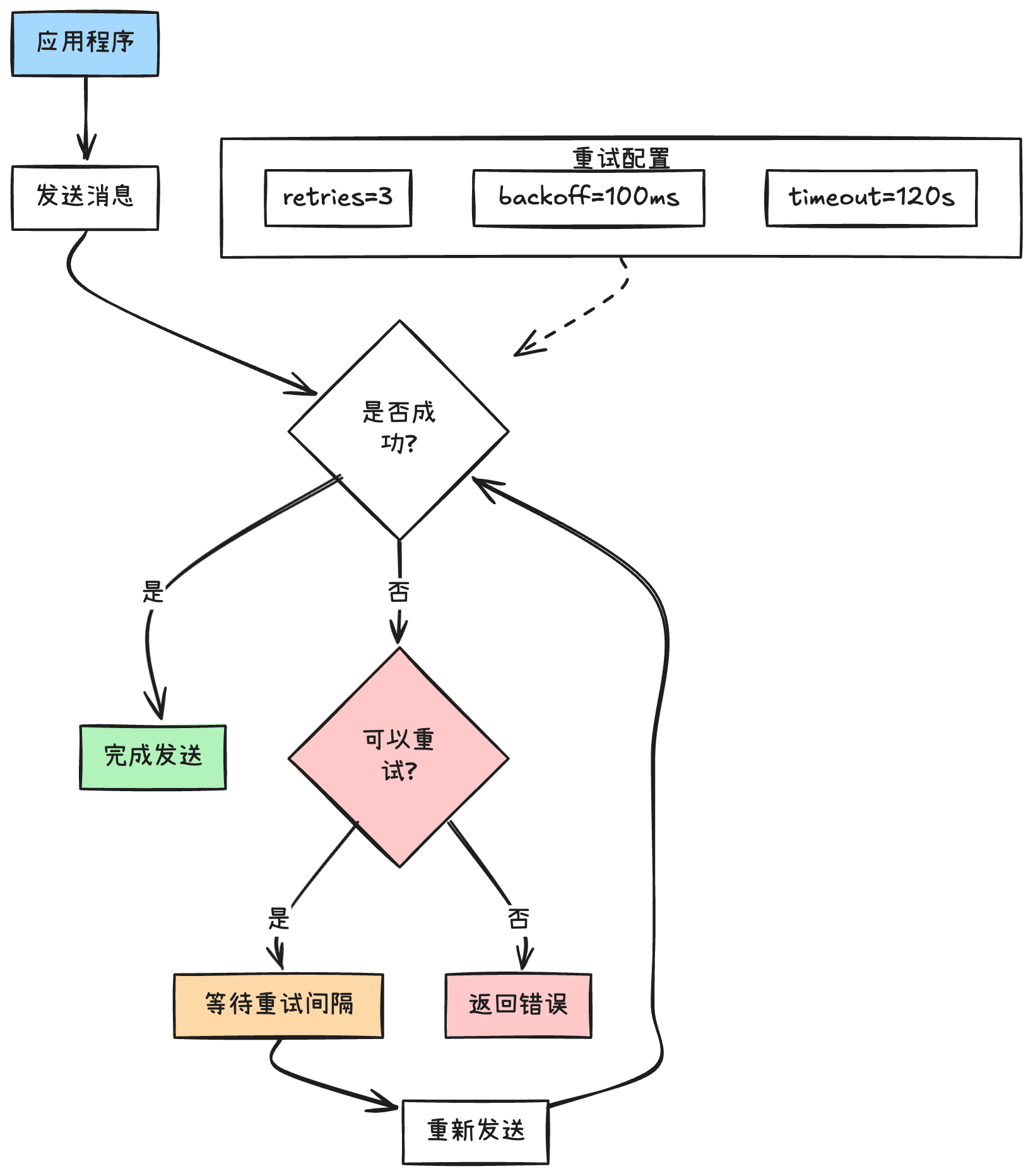
Producer 重试机制的基本流程
关键配置参数
1. retries
# 重试次数配置
retries=3 # 重试3次
2. retry.backoff.ms
# 重试间隔时间
retry.backoff.ms=100 # 基础重试间隔100ms
注意:从 Kafka 2.1 版本开始,Producer 默认使用指数退避策略。每次重试的实际等待时间会逐渐增加:
- 第1次重试:等待 100ms
- 第2次重试:等待 200ms
- 第3次重试:等待 400ms 这种策略可以避免在持续故障时造成无谓的频繁重试。
3. delivery.timeout.ms
# 消息发送总超时时间
delivery.timeout.ms=120000 # 总共等待2分钟
4. enable.idempotence
# 启用幂等性,避免重试导致的消息重复
enable.idempotence=true
强烈建议在生产环境中启用幂等性,它能确保即使在发生重试的情况下,每条消息也只会被成功写入一次。
实际场景分析
场景一:网络抖动
当发生网络抖动时,Producer 的重试机制会这样工作:
发送消息 ❌ 网络超时
↓
等待 100ms 后重试
↓
重试成功 ✅ 消息已送达
场景二:Broker 故障转移
当一个 Broker 发生故障,Kafka 会自动选举新的 Leader:
发送消息 ❌ Leader 不可用
↓
等待 100ms(此时集群在进行 Leader 选举)
↓
重试发送 ✅ 新 Leader 已上线,消息送达
最佳实践
-
启用幂等性
- 避免重试导致的重复消息
- 配置
enable.idempotence=true
-
合理设置重试次数
- 根据业务容忍度设置
- 避免无限重试
-
监控重试指标
- 监控重试次数
- 设置告警阈值
小结
合理配置 Producer 的重试机制,可以在保证消息可靠性的同时,避免过度重试带来的性能问题。这是构建可靠消息系统的关键一环。
相关推荐: